#1. 데이터수집
> population=read.csv('C:/Users/g_julian5383/Downloads/서울특별시 서대문구_주민등록 인구수_20210831.csv')
#주제: 서대문구 주민등록수 분석하기, 전체인구에서 해당 성별과 나이의 인구수에 따른 비율 조사하고 예측하기
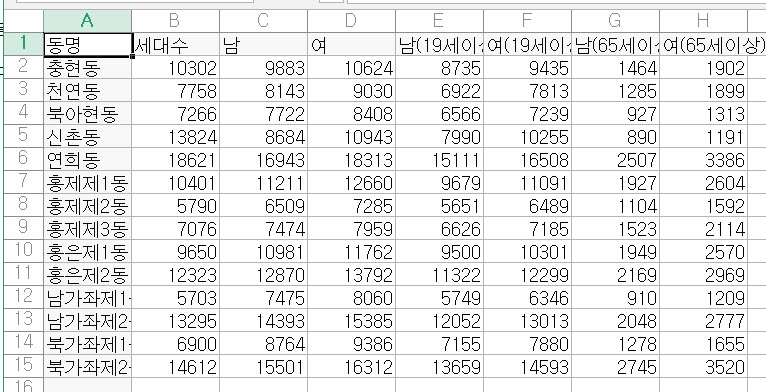
> population
동명 세대수 남 여 남.19세이상. 여.19세이상. 남.65세이상. 여.65세이상.
1 충현동 10302 9883 10624 8735 9435 1464 1902
2 천연동 7758 8143 9030 6922 7813 1285 1899
3 북아현동 7266 7722 8408 6566 7239 927 1313
4 신촌동 13824 8684 10943 7990 10255 890 1191
5 연희동 18621 16943 18313 15111 16508 2507 3386
6 홍제제1동 10401 11211 12660 9679 11091 1927 2604
7 홍제제2동 5790 6509 7285 5651 6489 1104 1592
8 홍제제3동 7076 7474 7959 6626 7185 1523 2114
9 홍은제1동 9650 10981 11762 9500 10301 1949 2570
10 홍은제2동 12323 12870 13792 11322 12299 2169 2969
11 남가좌제1동 5703 7475 8060 5749 6346 910 1209
12 남가좌제2동 13295 14393 15385 12052 13013 2048 2777
13 북가좌제1동 6900 8764 9386 7155 7880 1278 1655
14 북가좌제2동 14612 15501 16312 13659 14593 2745 3520
#2. 탐색
> library("dplyr") #dplyr패키지를 작동한다.
> str(population) #population의 구조를 조사해서 혹시 계산하려는 값에 chr형식이 있는지 검사한다. 만약 int가 아닌 chr형식이 있으면 계산에서 오류가 난다.
'data.frame': 14 obs. of 8 variables:
$ 동명 : chr "충현동 " "천연동 " "북아현동 " "신촌동 " ...
$ 세대수 : int 10302 7758 7266 13824 18621 10401 5790 7076 9650 12323 ...
$ 남 : int 9883 8143 7722 8684 16943 11211 6509 7474 10981 12870 ...
$ 여 : int 10624 9030 8408 10943 18313 12660 7285 7959 11762 13792 ...
$ 남.19세이상.: int 8735 6922 6566 7990 15111 9679 5651 6626 9500 11322 ...
$ 여.19세이상.: int 9435 7813 7239 10255 16508 11091 6489 7185 10301 12299 ...
$ 남.65세이상.: int 1464 1285 927 890 2507 1927 1104 1523 1949 2169 ...
$ 여.65세이상.: int 1902 1899 1313 1191 3386 2604 1592 2114 2570 2969 ...
> table(is.na(population)) #결측값이 있는지 검사한다. FALSE만 떴기 때문에 결측값은 없다.
FALSE
112
> View(population) #View를 통해서 데이터 셋을 출력한다.
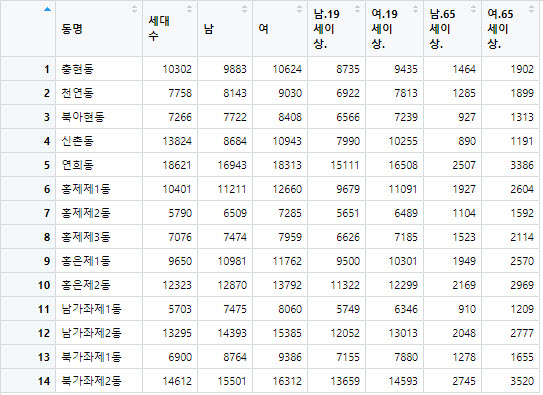
#3. 전처리및 가공
> population$전체인구<-round(population$남+population$여)
# population에 전체인구열을 만들기

> clean_population=population[,c(1,5,6,7,8,9)]
#데이터 분석을 위해서 분석을 원하는 열만 뽑아낸다. 전체인구에 따른 해당 나이와 성별의 비율을 분석하려고 했기에 “동명(1열), 남.19세이상.(5열), 여.19세이상.(6열), 남.65세이상.(7열), 여.65세이상.(8열), 전체인구(9열)”를 뽑아낸다.
> clean_population #population에서 추출해서 만들 데이터로 clean_population을 만들어낸다.
동명 남.19세이상. 여.19세이상. 남.65세이상. 여.65세이상. 전체인구
1 충현동 8735 9435 1464 1902 20507
2 천연동 6922 7813 1285 1899 17173
3 북아현동 6566 7239 927 1313 16130
4 신촌동 7990 10255 890 1191 19627
5 연희동 15111 16508 2507 3386 35256
6 홍제제1동 9679 11091 1927 2604 23871
7 홍제제2동 5651 6489 1104 1592 13794
8 홍제제3동 6626 7185 1523 2114 15433
9 홍은제1동 9500 10301 1949 2570 22743
10 홍은제2동 11322 12299 2169 2969 26662
11 남가좌제1동 5749 6346 910 1209 15535
12 남가좌제2동 12052 13013 2048 2777 29778
13 북가좌제1동 7155 7880 1278 1655 18150
14 북가좌제2동 13659 14593 2745 3520 31813
> str(clean_population) #구조를 확인해서 계산하려는 값이 chr형식이 있는지 확인한다.
'data.frame': 14 obs. of 6 variables:
$ 동명 : chr "충현동 " "천연동 " "북아현동 " "신촌동 " ...
$ 남.19세이상.: int 8735 6922 6566 7990 15111 9679 5651 6626 9500 11322 ...
$ 여.19세이상.: int 9435 7813 7239 10255 16508 11091 6489 7185 10301 12299 ...
$ 남.65세이상.: int 1464 1285 927 890 2507 1927 1104 1523 1949 2169 ...
$ 여.65세이상.: int 1902 1899 1313 1191 3386 2604 1592 2114 2570 2969 ...
$ 전체인구 : num 20507 17173 16130 19627 35256 ...
> View(clean_population) #clean_population표를 출력한다.
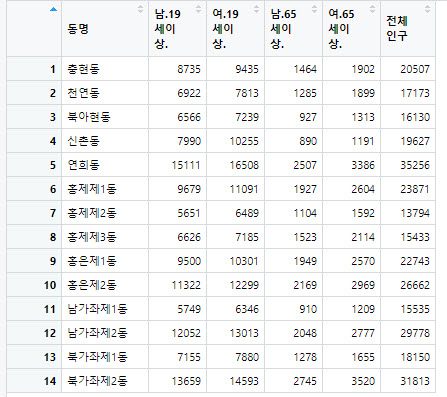
> clean_population$남.19세비율.<-round(clean_population$남.19세이상./clean_population$전체인구*1,digit=2)
> clean_population$여.19세비율.<-round(clean_population$여.19세이상./clean_population$전체인구*1,digit=2)
> clean_population$남.65세비율.<-round(clean_population$남.65세이상./clean_population$전체인구*1,digit=2)
> clean_population$여.65세비율.<-round(clean_population$여.65세이상./clean_population$전체인구*1,digit=2)
# 해당 성별과 나이별에 따른 비율을 만든다. 비율은 (성,나이인구수/전체인구)*1을 해서 소수점 비율을 만들어낸다. 또한 반올림을 할 수 있도록 round를 사용한다.

#비율을 생성하고 난 뒤의 표
#4. 분석
> summary(clean_population)
| 동명 | 남.19세이상. | 여.19세이상. | 남.65세이상. | 여.65세이상. | 전체인구 | 남.19세비율. | 여.19세비율. | 남.65세비율. | 여.65세비율. |
| Length:14 | Min. : 5651 | Min. : 6346 | Min. : 890 | Min. :1191 | Min. :13794 | Min. :0.3700 | Min. :0.4100 | Min. :0.05000 | Min. :0.060 |
| Class :character | 1st Qu.: 6700 | 1st Qu.: 7382 | 1st Qu.:1148 | 1st Qu.:1608 | 1st Qu.:16391 | 1st Qu.:0.4025 | 1st Qu.:0.4500 | 1st Qu.:0.07000 | 1st Qu.:0.090 |
| Mode :character | Median : 8362 | Median : 9845 | Median :1494 | Median :2008 | Median :20067 | Median :0.4100 | Median :0.4600 | Median :0.07000 | Median :0.105 |
| Mean : 9051 | Mean :10032 | Mean :1623 | Mean :2193 | Mean :21891 | Mean :0.4114 | Mean :0.4571 | Mean :0.07429 | Mean :0.100 | |
| 3rd Qu.:10911 | 3rd Qu.:11997 | 3rd Qu.:2023 | 3rd Qu.:2734 | 3rd Qu.:25964 | 3rd Qu.:0.4275 | 3rd Qu.:0.4675 | 3rd Qu.:0.08000 | 3rd Qu.:0.110 | |
| Max. :15111 | Max. :16508 | Max. :2745 | Max. :3520 | Max. :35256 | Max. :0.4300 | Max. :0.5200 | Max. :0.10000 | Max. :0.140 |
#Summary명령어로 각 데이터 마다 최대,최솟값 등의 데이터들을 알아본다.
#5. 예측모델
# 해당 비율과 전체인구를 통해서 2019년에 해당 인구가 서대문구에 얼마나 있는지 예측한다.
> m_1=lm(남.19세비율.~전체인구,data=clean_population) #선형모델 lm사용
> m_1
Call:
lm(formula = 남.19세비율. ~ 전체인구, data = clean_population)
Coefficients:
(Intercept) 전체인구
3.869e-01 1.121e-06
> coef(m_1) #회귀 계수
(Intercept) 전체인구
3.868823e-01 1.121302e-06
> deviance(m_1) #잔차 제곱합
[1] 0.003228563
> m_2=lm(여.19세비율.~전체인구,data=clean_population)
> m_2
Call:
lm(formula = 여.19세비율. ~ 전체인구, data = clean_population)
Coefficients:
(Intercept) 전체인구
4.490e-01 3.737e-07
> coef(m_2)
(Intercept) 전체인구
4.489615e-01 3.737335e-07
> deviance(m_2)
[1] 0.007803189
> m_3=lm(남.65세비율.~전체인구,data=clean_population)
> m_3
Call:
lm(formula = 남.65세비율. ~ 전체인구, data = clean_population)
Coefficients:
(Intercept) 전체인구
6.781e-02 2.957e-07
> coef(m_3)
(Intercept) 전체인구
6.781151e-02 2.957492e-07
> deviance(m_3)
[1] 0.002291178
> m_4=lm(여.65세비율.~전체인구,data=clean_population)
> m_4
Call:
lm(formula = 여.65세비율. ~ 전체인구, data = clean_population)
Coefficients:
(Intercept) 전체인구
9.952e-02 2.216e-08
> coef(m_4)
(Intercept) 전체인구
9.951501e-02 2.215514e-08
> deviance(m_4)
[1] 0.00519971
csv 파일 출처: 공공데이터포털
'R > Data Analysis' 카테고리의 다른 글
| [R] 데이터 소스를 구할 수 있는 사이트 추천 (0) | 2023.06.13 |
|---|