[비트교육센터] 자바 기반 풀스택 개발자 양성 과정(Bigdata) 7일차
1. Seoul_CCTV
- 서울의 CCTV데이터로 데이터 분석을 하려고 한다.
1) 코딩문
[1]

- source폴더에 새로운 폴더 practice를 선언한다.
- 그리고 그안에 data폴더를 선언한다.
[2]

- data폴더에 파일 2개를 넣는다.
2) 코딩문
[1]
import numpy as np
import pandas as pdcctv_seoul = pd.read_csv('data/서울시 CCTV 설치운영 현황(자치구)-연도별.csv',
header=1,thousands=',',encoding='cp949')#첫줄은 날리고 시작함
cctv_seoul.head() #만약 파일이 안뜨면 해당 ipynb을 죽였다 띄여야 한다.- csv파일을 첫번째 열을 먼저 날리고 시작한다. header는 열 이름으로 사용할 행을 지정한다. header=1을 지정해 원본데이터에서 첫줄을 무시하고 읽으라고 한다.
- thousands=',' 는 천 단위 자리수 구분으로 콤마를 없애고 불러오는 것이다.
- encoding='cp949'은 한글 인코딩의 한 종류로 EUC-KR의 확장형이다.
--> 결과

[2]
cctv_seoul.drop([0],inplace=True)#인덱스0을 날렸다.
cctv_seoul.head()- 출력한 표에서 행의 인덱스0을 날리고 표를 출력한다.
- inplace=True는 기존 데이터에 변경된 설정으로 덮어쓴다는 것을 의미한다.
--> 결과

[3]
cctv_seoul.info()- info(): 데이터에 대한 전반적인 정보를 나타낸다.
--> 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25 entries, 1 to 25
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구분 25 non-null object
1 총계 25 non-null int64
2 2011년 이전 25 non-null int64
3 2011년 25 non-null int64
4 2012년 25 non-null int64
5 2013년 25 non-null int64
6 2014년 25 non-null int64
7 2015년 25 non-null int64
8 2016년 25 non-null int64
9 2017년 25 non-null int64
10 2018년 25 non-null int64
11 2019년 25 non-null int64
12 2020년 25 non-null int64
dtypes: int64(12), object(1)
memory usage: 2.7+ KB[4]
cctv_seoul.head()- 불러온 데이터의 상위 5개의 행을 출력한다.
--> 결과

[5]
cctv_seoul.rename(columns={cctv_seoul.columns[0]:'구별'},inplace=True)
cctv_seoul.head()- 컬럼명을 바꾼다.
- rename(columns={'기존이름' : '바꿀이름'}, inplace=True) 구성으로 컬럼 0번 인덱스에 있는 이름을 '구별'로 바꾸어준다.
--> 결과

3) 코딩문
[1]
pop_seoul=pd.read_csv('data/population.txt',header=2,delim_whitespace=True,
thousands=',')
pop_seoul.head()- header=2 : 데이터의 3번째 행부터 출력한다.
- delim_whitespace=True : 공백으로 구분된 파일을 읽을 때 사용한다.
- thousands=',' : 천 단위 자리수 구분으로 콤마를 없애고 불러온다.
--> 결과

[2]
pop_seoul.drop(['기간','세대','남자','여자','남자.1','여자.1',
'남자.2','여자.2','세대당인구'],axis=1,inplace=True)
pop_seoul.head()- drop함수는 데이터에서 열을 삭제하는 메소드이다.
- axis=1: 판다스에서 컬럼을 삭제한다.
- [ ]안에는 삭제한 컬럼명을 정해준다.
--> 결과

[3]
pop_seoul.rename(columns={pop_seoul.columns[0]:'구별',pop_seoul.columns[1]:'인구수',
pop_seoul.columns[2]:'한국인',
pop_seoul.columns[3]:'외국인',
pop_seoul.columns[4]:'고령자'},inplace=True)
pop_seoul.head()- rename함수: 컬럼의 이름을 바꿀때 이용된다.
- 인덱스로 선언해서 각각 무슨 이름으로 바꿀지 정한다.
--> 결과

[4]
pop_seoul.drop([0],inplace=True)
pop_seoul.head()- 인덱스 0번인 행을 삭제한다.
- axis=0은 default값이다.
--> 결과

4) 코딩문
[1]
cctv_seoul['구별'].unique()- unique(): 데이터의 고유값들이 어떤 종류들인지 알고 싶을때 사용한다.
- 컬럼 '구별'에 대한 고유값들을 알아본다.
--> 결과
array(['종로구', '중 구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구',
'도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구', '금천구',
'영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구'], dtype=object)[2]
pop_seoul['구별'].unique()--> 결과
array(['종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구',
'도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구', '금천구',
'영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구'], dtype=object)[3]
cctv_seoul.loc[cctv_seoul['구별']=='중 구','구별']='중구'
cctv_seoul['구별'].unique()- loc[행의 인덱싱 값, 열 값]: 행의 인덱싱 값은 컬럼의 '구별'에서 '중 구'의 값을 가진 값이다. 즉, 인덱싱 값은 2이다. 그리고 열 값인 '구별'에 위치한 값을 '중구'로 바꾸어 준다.
--> 결과
array(['종로구', '중구', '용산구', '성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구',
'도봉구', '노원구', '은평구', '서대문구', '마포구', '양천구', '강서구', '구로구', '금천구',
'영등포구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구'], dtype=object)[4]
cctv_seoul.info() #인덱스 25개--> 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25 entries, 1 to 25
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구별 25 non-null object
1 총계 25 non-null int64
2 2011년 이전 25 non-null int64
3 2011년 25 non-null int64
4 2012년 25 non-null int64
5 2013년 25 non-null int64
6 2014년 25 non-null int64
7 2015년 25 non-null int64
8 2016년 25 non-null int64
9 2017년 25 non-null int64
10 2018년 25 non-null int64
11 2019년 25 non-null int64
12 2020년 25 non-null int64
dtypes: int64(12), object(1)
memory usage: 2.7+ KB[5]
pop_seoul.info() #인덱스 25개--> 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 25 entries, 1 to 25
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구별 25 non-null object
1 인구수 25 non-null int64
2 한국인 25 non-null int64
3 외국인 25 non-null int64
4 고령자 25 non-null int64
dtypes: int64(4), object(1)
memory usage: 1.1+ KB[6]
cctv_seoul.sort_values(by='총계',ascending=True)- sort_values메소드는 값을 기준으로 레이블을 정렬하는 메소드이다.
- by='총계': 총계를 기준 정렬한다.
- ascending=True: 오름차순으로 정렬한다.(False는 내림차순)
--> 결과

[7]
cctv_seoul.sort_values(by='총계',ascending=False)- 총계를 기준으로 내림차순 정렬한다.
--> 결과

[8]
cctv_seoul['최근증가율']=(cctv_seoul['2016년']+cctv_seoul['2017년']
+cctv_seoul['2018년']+cctv_seoul['2019년']
+cctv_seoul['2020년'])/(cctv_seoul['2011년 이전']
+cctv_seoul['2011년']+cctv_seoul['2012년']
+cctv_seoul['2013년']+cctv_seoul['2014년']
+cctv_seoul['2015년'])*100
cctv_seoul.sort_values(by='최근증가율',ascending=False)- 최근증가율 칼럼을 추가한다.
- 2011년이전에서 2015년까지의 값을 더한후 2016에서 2020년까지 더한 값을 나누어 준다.
- 최근 증가율을 기준으로 내림차순으로 정렬한다.
--> 결과

5) 코딩문
[1]
pop_seoul.head()- pop_seoul의 상위 5개 행을 출력한다.
--> 결과

[2]
pop_seoul['외국인 비율']=pop_seoul['외국인']/pop_seoul['인구수']*100
pop_seoul['고령자 비율']=pop_seoul['고령자']/pop_seoul['인구수']*100
pop_seoul.head()- 외국인 비율, 고령자 비율 컬럼을 추가하고 해당 비율을 구한다.
--> 결과

[3]
pop_seoul.sort_values(by='인구수',ascending=False)--> 결과

[4]
pop_seoul.sort_values(by='외국인',ascending=False)--> 결과

[5]
pop_seoul.sort_values(by='외국인 비율',ascending=False)--> 결과
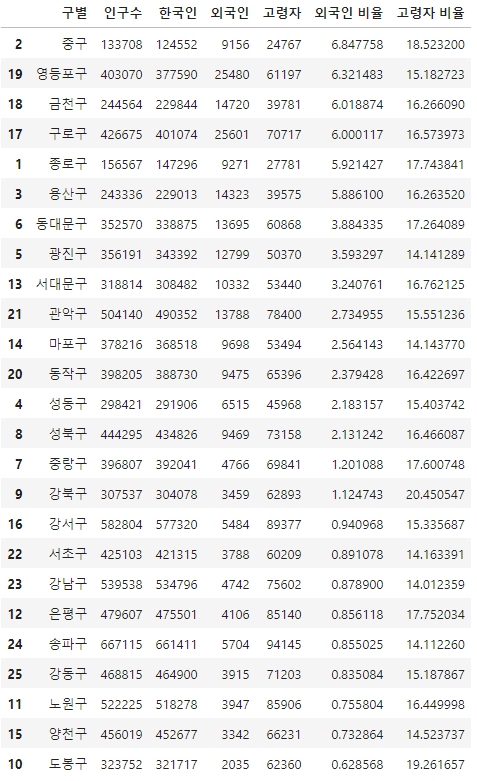
[6]
pop_seoul.sort_values(by='고령자',ascending=False)--> 결과

[7]
pop_seoul.sort_values(by='고령자 비율',ascending=False)--> 결과

6) 코딩문
[1]
data_result=pd.merge(cctv_seoul, pop_seoul, on='구별')
data_result.head()- merge: 두 객체를 병합하는 메소드이다.
- cctv_seoul과 pop_seoul을 '구별'기준으로 병합한다.
--> 결과

[2]
data_result.drop(['2011년 이전', '2011년', '2012년', '2013년', '2014년', '2015년', '2016년', \
'2017년', '2018년', '2019년', '2020년'], axis=1, inplace=True)
data_result.head()- data_result에서 버릴 칼럼을 정한다.
- axis=1: 열방향으로 삭제한다.
--> 결과

[3]
data_result.set_index('구별',inplace=True)
data_result.head()- set_index: 컬럼명(열)을 인덱스로 사용할수 있게 해주는 메소드이다.
--> 결과

[4]
data_result.to_csv('data/cctv_pop_seoul.csv',sep=',',encoding='utf-8')- data_result를 csv파일로 만들어준다.
- sep=',': csv파일의 구분자를 설정한다.
--> 결과

[5]
np.corrcoef(data_result['고령자 비율'],data_result['총계'])- corrcoef(): 피어슨 상관계수 값을 계산해준다.
--> 결과
array([[ 1. , -0.42943277],
[-0.42943277, 1. ]])[6]
np.corrcoef(data_result['외국인 비율'],data_result['총계'])--> 결과
array([[ 1. , -0.1694645],
[-0.1694645, 1. ]])[7]
np.corrcoef(data_result['인구수'],data_result['총계'])--> 결과
array([[1. , 0.45645369],
[0.45645369, 1. ]])7) 코딩문
[1]

- seaborn 라이브러리를 설치해준다.
import seaborn as sns
import matplotlib.pyplot as plt- seaborn 라이브러리를 import한다.
- seaborn
1) 파이썬 데이터 시각화 라이브러리이다.
2) matplotlib 대비 손쉽게 그래프를 그리고 그래프 스타일 설정을 할 수 있다는 장점이 있다.
[2]
import platform
from matplotlib import font_manager, rc # Runtime Configuration
path = "c:/Windows/Fonts/malgun.ttf"
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~~')- 운영체제에 따른 글꼴설정 if문이다.
sns.pairplot(data_result, x_vars=['고령자 비율','외국인 비율','인구수'],
y_vars=['총계'],kind='reg',height=3)
plt.show()- pairplot: 데이터에 들어 있는 각 컬럼(열)들의 모든 상관 관계를 출력한다.
- x_vars와 y_vars: 각각 x와 y에 어떤 값을 배치할지 설정한다.
- kind='reg': 어떤 종류의 그래프를 출력할지 설정한다.(reg는 일반그래프)
- height: 인치당 눈금 몇 개 설정할 지 설정한다.
--> 결과

[3]
data_result.sort_values(by='총계',ascending=False)--> 결과

[4]
data_result['총계'].plot(kind='barh',grid=True,figsize=(10,10))
plt.show()- kind: 플로팅할 유형을 선택한다. (barh: 세로그래프)
- grid: 격자를 설정
- figsize: 출력할 fig의 크기입니다.
--> 결과

[5]
data_result['총계'].sort_values().plot(kind='barh',grid=True,figsize=(10,10))
plt.show()- sort_values()를 붙여 크기별로 그래프를 정렬해준다.
--> 결과

[6]
plt.scatter(data_result['인구수'],data_result['총계'],s=50)
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.show()- Scatter plot(산점도)은 두 변수의 상관 관계를 직교 좌표계의 평면에 점으로 표현하는 그래프이다.
- 인구수, 총계값에 해당하는 위치에 기본 마커가 표시된다.
- s는 크기로 마커의 크기를 설정한다.
--> 결과

[7]
fp=np.polyfit(data_result['인구수'],data_result['총계'],1)
fp- polyfit함수는 주어진 데이터에 대해 최소 제곱을 갖는 다항식 피팅을 반환합니다.
- 차수+1(함수에서 1이 차수이다.)만큼의 숫자 배열이 반환된다.
--> 결과
array([4.03056886e-03, 1.43272762e+03])---
f1=np.poly1d(fp)
fx=np.linspace(100000,700000,100)- poly1d는 다항식 생성 함수로 입력배열을 항으로 간주해 다항식을 생성한다.
- linspace: 1차원 배열 만들기, 그래프 그리기에서 수평축의 간격 만들기 등에 사용된다.
---
plt.scatter(data_result['인구수'],data_result['총계'],s=50)
plt.plot(fx,f1(fx),ls='dashed',color='g')
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid()
plt.show()- plot함수에서 ls는 그래프 모양을 설정할 수 있다.
- plot함수는 분포도에서 평균값을 구한 막대그래프이다.
--> 결과

[8]
data_result['오차']=np.abs(data_result['총계']-f1(data_result['인구수']))
df_sort = data_result.sort_values(by='오차',ascending=False)
df_sort.head()- data_result에 오차 컬럼을 생성해 준다.
--> 결과
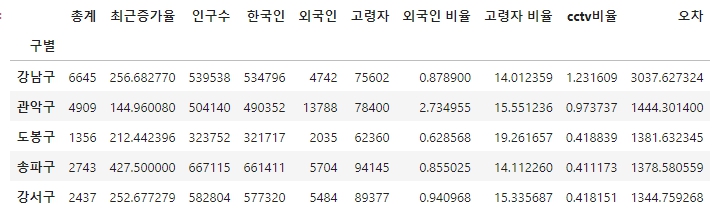
[9]
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'],data_result['총계'],s=50,c=data_result['오차'])
plt.plot(fx,f1(fx),ls='dashed',color='g')
for n in range(10):
plt.text(df_sort['인구수'][n]*1.02,df_sort['총계'][n]*0.98,
df_sort.index[n],fontsize=15)
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.colorbar()
plt.grid()
plt.show()- 인구수, 총계에 따라 산점도에 지역구 텍스트를 삽입한다.
--> 결과

8) 코딩문
[1]

- conda install folium을 실행해 folium라이브러리를 설치한다.
- folium: 지도를 그랴주는 Python 모듈이다.
https://python-visualization.github.io/folium/quickstart.html#Markers
Quickstart — Folium 0.14.0 documentation
Polylines folium can show linear elements on a map using PolyLine. This object can help put emphasis on a trail, a road, or a coastline. m = folium.Map(location=[-71.38, -73.9], zoom_start=11) trail_coordinates = [ (-71.351871840295871, -73.655963711222626
python-visualization.github.io
import folium
import json- json은 데이터를 문자열의 형태로 나타내기 위해 사용되는 언어이다.
- folium과 json을 import한다.
- 해당 파일은 서울 지역구에 대한 위치와 정보를 담은 json파일이다.

- 해당파일은 practive/data경로에 집어넣는다.
[2]
geo_path='data/seoul_geo.json'
geo_str=json.load(open(geo_path,encoding='utf-8'))- json파일을 실행한다.
map = folium.Map(location=[37.5502, 126.982],zoom_start=11)
#Map함수에 지정할 위도와 경도를 location값으로 입력한다.
folium.Choropleth(
geo_data=geo_str,#경계선 좌표값이 담긴 데이터(json파일에 있다.)
data = data_result['cctv비율'],#cctv비율에 대한 데이터를 넣는다.
columns=[data_result.index, data_result['cctv비율']],#어떤 컬럼값을 넣을지 결정한다.
fill_color='PuRd',#밀집도에 따른 색상의 변화이다. 보라색에서 붉은색으로 간다.
key_on='feature.id'#어떤 칼럼이 feature하고 매칭되는지 인식
).add_to(map)
map- fill_color관련 사이트
https://matplotlib.org/stable/tutorials/colors/colormaps.html
Choosing Colormaps in Matplotlib — Matplotlib 3.7.1 documentation
Note Click here to download the full example code Choosing Colormaps in Matplotlib Matplotlib has a number of built-in colormaps accessible via matplotlib.colormaps. There are also external libraries that have many extra colormaps, which can be viewed in t
matplotlib.org
--> 결과

2. Police
- 각 경찰서마다 수사한 범죄건수에 관련된 데이터 분석이다.
1) 코딩문
[1]
import pandas as pd
import numpy as np
- police_2000_2020.csv를 다운받아서 data폴더 안에 넣어준다.
[2]
crime_police=pd.read_csv('data/police_2000_2020.csv',encoding='cp949')
crime_police.head(10)- 해당 csv파일을 읽어온다. euc-kr타입이기 때문에 인코딩이 필수이다.
-->결과
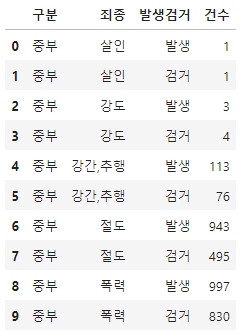
[3]
crime_police.set_index(['구분','죄종','발생검거'],inplace=True)
crime_police.head(10)- set_index함수로 열 3개의 멀티인덱스를 지정한다.
--> 결과

[4]
crime_police=crime_police.unstack(-1)
crime_police.head(10)- unstack을 선언해 행을 언피벗해 하위 열로 변환하는 메소드이다.
- level: 멀티인덱스일 경우 하위열로 변환할 행의 레벨이다. 디폴트값은 -1이다.
--> 결과

[5]
crime_police=crime_police.unstack(-1)
crime_police.head(10)--> 결과

[6]
crime_police=crime_police.droplevel(0,axis=1) #컬럼의 첫번째 레벨을 드롭시킴
crime_police.head(10) #컬럼 맨 윗단이 사라졌다.--> 결과
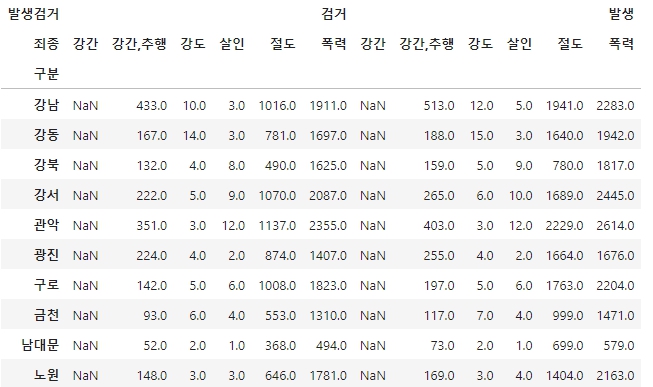
[7]
col_dict1 = ['검거nan','강간검거', '강도검거', '살인검거', '절도검거', '폭력검거']
col_dict2 = ['발생nan','강간발생', '강도발생', '살인발생', '절도발생', '폭력발생']
#새로운 컬럼이름을 미리정함
c1 = crime_police['검거'].rename(
columns={crime_police['검거'].columns[i]:j for i, j in enumerate(col_dict1)})
c2 = crime_police['발생'].rename(
columns={crime_police['발생'].columns[i]:j for i, j in enumerate(col_dict2)})
#기존은 컬럼이 무려 2레벨이어서 rename을 이용해 검거에 관련된 컬럼과 발생에 관련된 컬럼들을
# col_dict1, col_dict2로 순서대로 변경해준다.
crime_police = pd.merge(c1, c2, on='구분')
crime_police.head()--> 결과

[8]
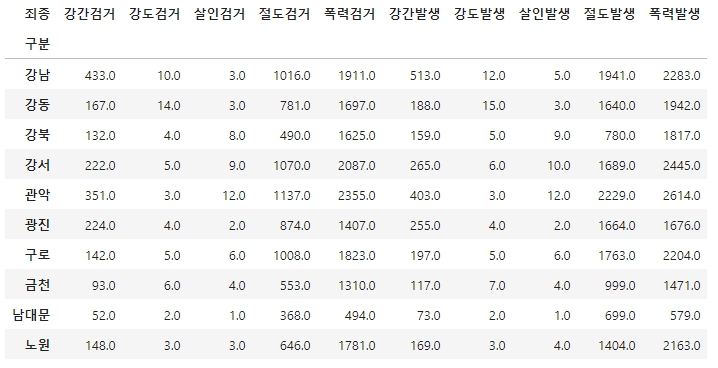
crime_police.drop(['검거nan', '발생nan'], axis=1, inplace=True)
crime_police.head(10)- 컬럼 검서nan, 발생nan을 열단위로 삭제한다.
--> 결과
2) 코딩문
[1]

- 터미널에서 conda install googlemap을 입력해서 라이브러리를 다운받는다.
- 그러나 조회하려는 googlemaps 패키지가 없어서 다운로드가 안된다.
https://anaconda.org/conda-forge/googlemaps
Googlemaps :: Anaconda.org
Description Use Python? Want to geocode something? Looking for directions? Maybe matrices of directions? This library brings the Google Maps API Web Services to your Python application. Analytics
anaconda.org

- 아니콘다 사이트에서 Googlemaps 관련 installers코드를 조회한다.

- conda install -c conda-forge googlemaps를 입력해서 googlemaps 라이브러리를 다운받는다.
[2]
import googlemaps- Google Maps Geolocation API: 구글 서비스의 이용자뿐 아니라 누구나 사용이 가능한 위치기반 서비스이다. WPS 위치 측위 방법을 지원하는 서비스로, 사용자가 확인 가능한 Wi-FI AP과 기지국의 정보를 기반으로 위치 정보를 제공한다.
(여담으로 API값은 다른분께 빌렸다.)
gmaps_key=''#받은 API값을 넣는다. 절대 아무에게나 공게하면 안된다.
gmaps = googlemaps.Client(key=gmaps_key)gmaps.geocode('서울중부경찰서',language='ko') #조회하는 언어가 한국어하는거 명시- 한국어 설정으로 서울중부경찰서의 결과값을 받아온다.
--> 결과
[{'address_components': [{'long_name': '27',
'short_name': '27',
'types': ['premise']},
{'long_name': '수표로',
'short_name': '수표로',
'types': ['political', 'sublocality', 'sublocality_level_4']},
{'long_name': '중구',
'short_name': '중구',
'types': ['political', 'sublocality', 'sublocality_level_1']},
{'long_name': '서울특별시',
'short_name': '서울특별시',
'types': ['administrative_area_level_1', 'political']},
{'long_name': '대한민국',
'short_name': 'KR',
'types': ['country', 'political']},
{'long_name': '100-032',
'short_name': '100-032',
'types': ['postal_code']}],
'formatted_address': '대한민국 서울특별시 중구 수표로 27',
'geometry': {'location': {'lat': 37.56361709999999, 'lng': 126.9896517},
'location_type': 'ROOFTOP',
'viewport': {'northeast': {'lat': 37.5649660802915,
'lng': 126.9910006802915},
'southwest': {'lat': 37.5622681197085, 'lng': 126.9883027197085}}},
'partial_match': True,
'place_id': 'ChIJc-9q5uSifDURLhQmr5wkXmc',
'plus_code': {'compound_code': 'HX7Q+CV 대한민국 서울특별시',
'global_code': '8Q98HX7Q+CV'},
'types': ['establishment', 'point_of_interest']}]- 여기에서 formatted_address와 geometry를 이용할 것이다.
[3]
station_name=[]
for name in crime_police.index:
station_name.append('서울'+str(name)+'경찰서')
station_name- crime_police에서 인덱스 값을 가져와 station_name 리스트를 만든다.
--> 결과
['서울강남경찰서',
'서울강동경찰서',
'서울강북경찰서',
'서울강서경찰서',
'서울관악경찰서',
'서울광진경찰서',
'서울구로경찰서',
'서울금천경찰서',
'서울남대문경찰서',
'서울노원경찰서',
'서울도봉경찰서',
'서울동대문경찰서',
'서울동작경찰서',
'서울마포경찰서',
'서울방배경찰서',
'서울서대문경찰서',
'서울서부경찰서',
'서울서초경찰서',
'서울성동경찰서',
'서울성북경찰서',
'서울송파경찰서',
'서울수서경찰서',
'서울양천경찰서',
'서울영등포경찰서',
'서울용산경찰서',
'서울은평경찰서',
'서울종로경찰서',
'서울종암경찰서',
'서울중랑경찰서',
'서울중부경찰서',
'서울혜화경찰서']---
print(len(station_name))- 리스트 길이를 알아본다.
--> 결과
31
3) 코딩문
[1]

- tqdm 라이브러리를 설치한다.(conda install tqdm)
- tqdm: for 루프와 같은 반복문에서 사용하여 현재 상태를 시각화하고, 진행률을 나타내며, 소요 시간 등을 보여준다.
from tqdm.notebook import tqdm
station_address=[]#주소
station_lat=[]#위도
station_lng=[]#경도
for name in tqdm(station_name):
tmp=gmaps.geocode(name,language='ko')
# 'name'의 구글 geocode 를 가져옴. 이 때 name 은 station_name 으로 찾는다. 언어는 한국어
station_address.append(tmp[0].get('formatted_address'))
# dictionary 형태 이기에 keys값(formatted_address)으로 values 값을 가져온다
station_lat.append(tmp[0].get('geometry')['location']['lat'])
#리스트에서 위도를 추출
#keys값 : ('geometry')['location']['lat']
station_lng.append(tmp[0].get('geometry')['location']['lng'])
#리스트에서 경도를 추출
# keys값 : ('geometry')['location']['lng']
print(name + ': '+ tmp[0].get('formatted_address'))
# 마지막 출력은 formatted_address(keys값)의 values
#각 list (station_address, station_lat, station_lng) 에는 주소, 위도, 경도 모두 저장되어있는 상태--> 결과
서울강남경찰서: 대한민국 서울특별시 강남구 테헤란로114길 11
서울강동경찰서: 대한민국 서울특별시 강동구 성내로 57
서울강북경찰서: 대한민국 서울특별시 강북구 오패산로 406
서울강서경찰서: 대한민국 서울특별시 양천구 신월동 화곡로 73
서울관악경찰서: 대한민국 서울특별시 관악구 관악로5길 33
서울광진경찰서: 대한민국 서울특별시 광진구 구의동 자양로 167
서울구로경찰서: 대한민국 서울특별시 구로구 새말로 97 신도림테크노마트 5층
서울금천경찰서: 대한민국 서울특별시 금천구 시흥대로73길 50
서울남대문경찰서: 대한민국 서울특별시 중구 한강대로 410
서울노원경찰서: 대한민국 서울특별시 노원구 노원로 283
서울도봉경찰서: 대한민국 서울특별시 도봉구 노해로 403
서울동대문경찰서: 대한민국 서울특별시 동대문구 약령시로21길 29
서울동작경찰서: 대한민국 서울특별시 동작구 노량진로 148
서울마포경찰서: 대한민국 서울특별시 마포구 마포대로 183
서울방배경찰서: 대한민국 서울특별시 서초구 동작대로 204
서울서대문경찰서: 대한민국 서울특별시 서대문구 통일로 113
서울서부경찰서: 대한민국 서울특별시 은평구 진흥로 58
서울서초경찰서: 대한민국 서울특별시 서초구 서초3동 반포대로 179
서울성동경찰서: 대한민국 서울특별시 성동구 행당동 왕십리광장로 9
서울성북경찰서: 대한민국 서울특별시 성북구 삼선동 보문로 170
서울송파경찰서: 대한민국 서울특별시 송파구 중대로 221
서울수서경찰서: 대한민국 서울특별시 강남구 개포로 617
서울양천경찰서: 대한민국 서울특별시 양천구 목동동로 99
서울영등포경찰서: 대한민국 서울특별시 영등포구 국회대로 608
서울용산경찰서: 대한민국 서울특별시 용산구 백범로 329
서울은평경찰서: 대한민국 서울특별시 은평구 연서로 365
서울종로경찰서: 대한민국 서울특별시 종로구 인사동5길 41
서울종암경찰서: 대한민국 서울특별시 종암경찰서
서울중랑경찰서: 대한민국 서울특별시 중랑구 묵제2동 249-2
서울중부경찰서: 대한민국 서울특별시 중구 수표로 27
서울혜화경찰서: 대한민국 서울특별시 종로구 창경궁로 112-16[2]
print(len(station_address),len(station_lat),len(station_lng))- 주소, 위도, 경도 리스트의 길이를 출력한다.
--> 결과
31 31 31[3]
print(station_lat[:10])--> 결과
[37.5094352, 37.528511, 37.63719740000001, 37.5397827, 37.4743945, 37.5428231, 37.5074418, 37.4568129, 37.5547584, 37.6421389]---
print(station_lng[:10])--> 결과
[127.0669578, 127.1268224, 127.0273048, 126.8299968, 126.9513489, 127.0838395, 126.8902237, 126.8968061, 126.9734981, 127.0710473][4]
crime_police.head()--> 결과

[5]
gu_name=[]
for name in station_address:
tmp = name.split()
tmp_gu = [gu for gu in tmp if gu[-1] == '구'][0]
#조회한 주소들을 띄어쓰기로 나누었을때
#단어 끝에 '구'가 있는 것들은 전부 추출
gu_name.append(tmp_gu)
crime_police['구별']=gu_name
crime_police.head()--> 결과

---
test=['대한민국','서울특별시','관악구','나머지주소']
print([gu for gu in test if gu[-1] == '구'][0])- 해당처럼 구에 관련된 글자를 추출한다.
--> 결과
관악구
[6]
crime_police.reset_index(drop=False, inplace=True)
crime_police- reset_index: 설정 인덱스를 제거하고 기본 인덱스(0,1,2, ... , n)으로 변경하는 메서드dlek.
- drop: 제거한 인덱스를 열에 추가할지 여부이다. 기본값은 False로 제거된 인덱스는 열로 반환된다.
- inplace: pandas공통 인수로, 원본을 변경할지 여부이다.
--> 결과

[7]
crime_police.loc[crime_police['구분']=='도봉','강간검거']=87
crime_police- NaN값인 도봉구의 '강간검거'값을 87로 변경해준다.
--> 결과

[8]
crime_police.loc[crime_police['구분']=='도봉','강간발생']=82
crime_police.loc[crime_police['구분']=='방배','강간검거']=50
crime_police.loc[crime_police['구분']=='방배','강간발생']=63
crime_police.loc[crime_police['구분']=='성북','강간검거']=77
crime_police.loc[crime_police['구분']=='성북','강간발생']=95
crime_police.loc[crime_police['구분']=='양천','강간검거']=90
crime_police.loc[crime_police['구분']=='양천','강간발생']=109
crime_police.loc[crime_police['구분']=='종암','강간검거']=44
crime_police.loc[crime_police['구분']=='종암','강간발생']=47
crime_police- 다른 Nan값도 전부 채워준다.
[9]
crime_anal=pd.pivot_table(crime_police, index='구별',aggfunc=np.sum)
crime_anal- pivot table: 데이터 열 중에서 두 개의 열을 각각 행 인덱스, 열 인덱스로 사용하여 데이터를 조회하여 펼쳐놓은 것을 말한다.
- index: 인덱스를 정한다.
- aggfunc: 산식을 설정한다. 평균값이 아닌 합계로 설정했다.
--> 결과

[10]
crime_anal['강간검거율'] = crime_anal['강간검거']/crime_anal['강간발생']*100
crime_anal['강도검거율'] = crime_anal['강도검거']/crime_anal['강도발생']*100
crime_anal['살인검거율'] = crime_anal['살인검거']/crime_anal['살인발생']*100
crime_anal['절도검거율'] = crime_anal['절도검거']/crime_anal['절도발생']*100
crime_anal['폭력검거율'] = crime_anal['폭력검거']/crime_anal['폭력발생']*100- 새로운 칼럼 5개를 추가한다. 각 검거에 대한 검거율 값들이다.
del crime_anal['강간검거']
del crime_anal['강도검거']
del crime_anal['살인검거']
del crime_anal['절도검거']
del crime_anal['폭력검거']crime_anal.head()- 그리고 5개의 칼럼을 삭제한다.
--> 결과

[11]
crime_anal--> 결과
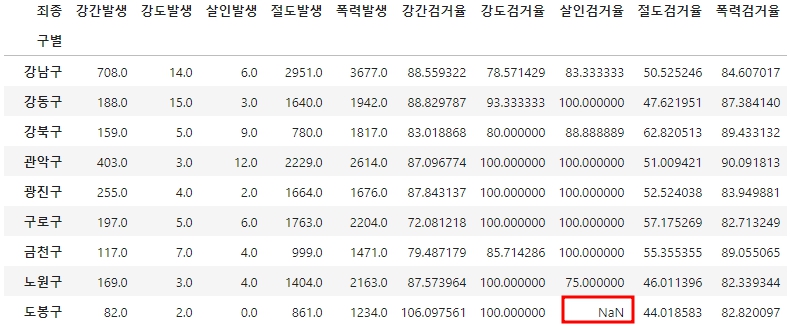
- 도봉구 살인 검거율에 NaN이 있다.
- 이는 살인 발생 값이 0이 되어서 연산 오류가 일어난것이다.
---
crime_anal=crime_anal.fillna(0)
crime_anal- NaN값을 없애기 위해 fillna함수를 이용해 결측값을 원하는 값으로 변경한다.
--> 결과

[12]
col_list = ['강간검거율', '강도검거율', '살인검거율',
'절도검거율', '폭력검거율']
for column in col_list:
crime_anal.loc[crime_anal[column] > 100, column] = 100
crime_anal- 해당 컬럼들중 수치가 100퍼가 넘어가는 값들을 전부 100으로 바꾸어준다.
--> 결과

[13]
crime_anal.rename(columns = {'강간발생':'강간',
'강도발생':'강도',
'살인발생':'살인',
'절도발생':'절도',
'폭력발생':'폭력'}, inplace=True)
crime_anal.head()- 발생이 붙은 칼럼 값들을 간단하게 바꾸어준다.
--> 결과

4) 코딩문
[1]

- scikit-learn 라이브러리를 설치한다.
- conda install scikit-learn
- scikit-learn은 파이썬 프로그래밍 언어용 자유 소프트웨어 기계 학습 라이브러리이다.
[2]
from sklearn import preprocessing
col = ['강간', '강도', '살인', '절도', '폭력']
x = crime_anal[col].values- 사이킷런 라이브러리를 선언하고 해당 칼럼들에 대한 값을 받는다.
[3]
print(type(x))--> 결과
<class 'numpy.ndarray'>---
print(x.dtype)--> 결과
float64
[4]
print(x[:3])--> 결과
[[7.080e+02 1.400e+01 6.000e+00 2.951e+03 3.677e+03]
[1.880e+02 1.500e+01 3.000e+00 1.640e+03 1.942e+03]
[1.590e+02 5.000e+00 9.000e+00 7.800e+02 1.817e+03]]---
min_max_scaler=preprocessing.MinMaxScaler()
x_scaled=min_max_scaler.fit_transform(x)
print(x_scaled[:3])- MinMaxScaler함수로 정규화로 전처리한다.
- 정규화는 모든 값을 0~1사이의 값으로 바꾸는 것이다. 음수도 전부다 바뀐다.
- ( X- (X의 최솟값) ) / ( X의 최댓값 - X의 최솟값 ) 이다.
- fit_transformers(): 객체를 생성해 표준화와 마찬가지로 fit으로 학습시킨뒤 transform을 사용해 변환한다.
--> 결과
[[1. 0.92857143 0.4 0.89488871 0.87517832]
[0.16932907 1. 0.2 0.35449299 0.2564194 ]
[0.12300319 0.28571429 0.6 0. 0.21184023]][5]
crime_anal_norm = pd.DataFrame(x_scaled, columns=col,
index = crime_anal.index)
crime_anal_norm- 표준화한 값을 이용해 dataframe으로 만든다.
- x_scaled 데이터로 DataFrame의 데이터를 생성한다.
- columns: 각 칼럼에 대한 라벨을 추가한다.
- index: 각 행에 대한 라벨을 추가한다.
--> 결과

[6]
col2 = ['강간검거율', '강도검거율', '살인검거율',
'절도검거율', '폭력검거율']
crime_anal_norm[col2] = crime_anal[col2]
crime_anal_norm.head()- crime_anal_norm 데이터프레임에 새로운 칼럼을 추가한다.
--> 결과
