[비트교육센터][AI] AI 4일차 Pytorch, 다중분류
1. Pytorch
1. 파이토치와 텐서플로우의 차이점
- numpy 와 비슷하지만 Ai 에서 tensor 는 3차원 이상을 의미한다
- numpy와의 차이점이라면 tensor는 기울기를 구해주는 식을 자체적으로 가지고 있다.
2. 예제
[1] csv 파일 넣기
- 작업하는 경로에 해당 csv 파일을 입력한다.
[2] 정확도 계산
1) 모듈 임포트, gpu 사용여부
import torch
import numpy as np
#파이토치를 사용하기 위해 torch 모듈을 임포트한다.device = ('cuda' if torch.cuda.is_available() else 'cpu')
#pytorch 는 gpu를 사용할지 cpu를 사용할지 코드 상에서 구분 할 수 있다.torch.cuda.is_available()
#해당 식이 True 값이 나오면 gpu를 사용하는 것이고 false 값이 나오면 cpu로 동작한다.--> 결과
False2) csv 파일로드, 넘파일 배열 변환
data_set = np.loadtxt('data/ThoraricSurgery3.csv',delimiter=',')
#폐암 관련 데이터를 가진 csv 파일을 넘파이 배열로 로드한다.
data_set = torch.from_numpy(data_set)
#그 다음 넘파이 배열인 data_set을 파이토치 텐서로 변환한다.data_set.shape
#data_set의 형태를 출력한다.--> 결과
torch.Size([470, 17])- 샘플은 470개, 각 샘플은 17개(16개의 feature, 1개의 target)의 값으로 구성되었다.
3) 입력변수(X), 목표변수(y) 추출
X = data_set[:, :-1]
# 데이터셋의 모든 샘플에 대해 마지막 열을 제외한 특성으로 이루어진 행렬이다.
y = data_set[:, -1]
# 데이터셋의 모든 샘플에 대해 마지막 열의 값들로 이루어진 벡터이다.X.shape
# 형태를 알아본다.--> 결과
torch.Size([470, 16])- 샘플은 470개, 각 샘플은 16개(15개의 feature, 1개의 target)의 값으로 구성되었다.
y.shape
# 형태를 알아본다.--> 결과
torch.Size([470])- 총 470개의 샘플이 있다.
4) 인공신경망 모델 Surgery 구현
import torch.nn as nn
class Surgery(nn.Module):
#init은 모델의 구조를 정의하는 생성자이다.
#nn.Module클래스를 상성받아 생성자를 만들고 필요한 레이어를 초기화한다.
def __init__(self):
super(Surgery, self).__init__()
self.hidden_linear = nn.Linear(16,30)
#입력층과 은닉층 사이의 완전연결계층을 정의한다.
#입력 값은 16개고 은닉층의 출력값은 30개이다.
self.hidden_activation = nn.ReLU()
#출력값을 넣을 활성화 함수로 ReLU를 정의한다.
self.output_linear = nn.Linear(30,1)
#은닉층과 출력층 사이의 완전연결계층을 정의한다.
#은닉층의 입력값은 30개이고 출력값 1개이다.
self.output_activation = nn.Sigmoid()
#출력값을 넣을 활성화 함수로 Sigmoid를 정의한다.
#순전파 함수를 정의한다.
def forward(self, x):
x = self.hidden_linear(x)
#입력데이터 x를 입력층의 완전연결계층을 통과시킨다.
x = self.hidden_activation(x)
#입력층을 거친결과 ReLU활성화 함수를 적용한다.
x = self.output_linear(x)
#은닉층을 거친결과를 출력층의 완전연결계층을 통과시킨다.
x = self.output_activation(x)
#출력층을 거친결과에 Sigmoid활성화 함수를 적용한다.
#Sigmoid함수를 사용시 이 모델이 이진분류를 수행하기 때문이다.
return x
#예측값을 출력하는 함수이다.
def predict(self, x):
pred = self.forward(x)
#순전파 함수를 호출해 예측값을 얻는다.
if pred >= 0.5:
return 1
else:
return 0
#시그모이드 함수로 나오기 때문에
#예측값이 0.5보다 높으면 1로 보고, 낮으면 0으로 본다.model = Surgery().to(device)
# Surgery 클래스를 호출하고 to(device)를 통해 cpu로 클래스를 이동시킨다.
model
# model은 cpu에 올려진 인공신경망 모델이다. cpu에 데이터를 입력하고 예측값을 얻을 수 있다.--> 결과
Surgery(
(hidden_linear): Linear(in_features=16, out_features=30, bias=True)
(hidden_activation): ReLU()
(output_linear): Linear(in_features=30, out_features=1, bias=True)
(output_activation): Sigmoid()
)5) 모델 파리미터 반환
param_gen = model.named_parameters()#모델 파라미터를 반환하는 파이썬 제너레이터이다.
param_gen- 파이썬 제너레이터: iterator를 생성해주는 함수이다.
--> 결과
<generator object Module.named_parameters at 0x0000016A7602D3C0>6) iterator
next(param_gen)- next 함수: iterator 값을 출력한다.
--> 결과
('hidden_linear.weight',
Parameter containing:
tensor([[ 0.1411, -0.1960, 0.0544, -0.2382, -0.1926, -0.1387, 0.0303, -0.0380,
0.0116, 0.1834, -0.1816, 0.0169, -0.0408, 0.0976, -0.0479, -0.0467],
[ 0.0624, -0.1650, -0.0720, -0.1275, 0.0218, 0.2495, 0.1344, -0.0174,
-0.0051, -0.0460, 0.1676, -0.1328, 0.2260, 0.0975, -0.1880, -0.2194],
[-0.1642, -0.2300, -0.0594, 0.0662, -0.0571, -0.1797, -0.1625, -0.2354,
-0.0297, 0.1347, 0.2023, 0.2073, 0.1286, -0.0399, -0.0580, 0.0309],
...
[ 0.0060, -0.1857, 0.1219, 0.1489, -0.1304, -0.1230, 0.2015, 0.0654,
-0.0031, 0.0406, -0.0504, 0.1818, -0.1568, -0.0601, 0.0579, 0.0206],
[ 0.1764, 0.1386, -0.0704, 0.0582, 0.0819, -0.1159, -0.0941, -0.2153,
0.1791, 0.0131, 0.1028, 0.1817, 0.0769, 0.0251, -0.1384, 0.2231],
[ 0.0381, 0.0496, 0.1430, -0.1061, 0.2194, -0.1305, -0.2474, -0.0537,
-0.0032, -0.1205, -0.0312, 0.0541, 0.1344, -0.1372, -0.0045, -0.0635],
[-0.0398, -0.0350, -0.2257, 0.1289, 0.1225, 0.1153, 0.1657, 0.1972,
-0.2316, 0.1868, -0.1217, 0.1155, -0.0609, -0.0621, -0.0736, -0.1184]],
requires_grad=True))7) 파라미터의 개수 계산
#주어진 모델의 파라미터 수와 각 파라미터의 크기를 출력하는 함수이다.
def count_parameters(model):
total_param = 0 #파라미터를 저장할 변수이다.
for name, param in model.named_parameters():#모델의 이름과 파라미터를 가져온다.
if param.requires_grad: #파라미터가 학습 가능 경우에만 파라미터의 크기를 출력하고 계산한다.
num_param = np.prod(param.size())#파라미터의 크기를 가져온다.
if param.dim() > 1: #파라미터의 차원이 1보다 큰경우
print(name, ':', ' x '.join(str(x) for x in list(param.size())[::-1]), '=', num_param)
#파라미터의 크기를 x로 연결해 출력한다.
else: #파라미터 차원이 1인 경우
print(name, ':', num_param) #단일 숫자를 출력한다.
print('-' * 40)
total_param += num_param #파라미터의 크기를 변수에 저장하고 total_param에 더해준다.
print('total:', total_param)count_parameters(model) #파리미터의 개수 계산--> 결과
hidden_linear.weight : 16 x 30 = 480
hidden_linear.bias : 30
----------------------------------------
output_linear.weight : 30 x 1 = 30
output_linear.bias : 1
----------------------------------------
total: 541- 480+30+30+1=541
8) 손실값 출력
import torch.optim as optim
#파이토치에서 제공하는 최적화 알고리즘(Adam, RMSprop 등)을 제공하는 라이브러리다.
from torch.utils.data import DataLoader, TensorDataset
#파이토치에서 제공하는 데이터로딩(TensorDataset)과 미니배치(DataLoader) 처리를 위한 클래스이다.ds = TensorDataset(X,y)
#입력데이터 X와 라벨 y를 TensorDataset으로 묶어준다.
dataloader = DataLoader(ds, batch_size=10)
#TensorDataset을 사용해 데이터를 미니배치로 로드하는 DataLoader를 생성한다.
optimizer = optim.Adam(model.parameters())
#Adam 최적화 알고리즘을 사용해 모델의 파라미터를 최적화하는 옵티마이저를 정의한다.
n_epochs = 10
for epoch in range(n_epochs):
for data, label in dataloader:
out = model(data.type(torch.FloatTensor).to(device))
#순전파
loss = nn.BCELoss()(out, label.type(torch.FloatTensor).unsqueeze(1).to(device))
#calculate loss
#BCELoss는 예측값과 타겟값 사이의 교차 엔트로피(무질서도)를 계산해 손실값을 얻는다.
#unsqueeze: 차원을 늘려준다.
optimizer.zero_grad() #기울기 초기화
loss.backward() #개별 파라미터 기울기 계산
optimizer.step() #개별 파라미터 갱신
#loss와 step은 한세트이다.
print("Epoch: %d, Loss: %.4f"%(epoch, float(loss)))
#각 에포크 마다 현 에포크 번호와 손실 값을 출력한다.
#에포크: 전체 데이터 셋에 대해 학 번 학습이 아루어지는 단위--> 결과
Epoch: 0, Loss: 0.3074
Epoch: 1, Loss: 0.3037
Epoch: 2, Loss: 0.3024
Epoch: 3, Loss: 0.3008
Epoch: 4, Loss: 0.2986
Epoch: 5, Loss: 0.2963
Epoch: 6, Loss: 0.2940
Epoch: 7, Loss: 0.2918
Epoch: 8, Loss: 0.2895
Epoch: 9, Loss: 0.28739) 정확도 계산
train_loader = DataLoader(ds)
correct = 0 #모델이 예측한 총 데이터수
total = 0 #전체데이터수
with torch.no_grad():
for data, label in train_loader: #DataLader에서 data와 label을 가져온다.
data = data.type(torch.FloatTensor)
#데이터를 실수형으로 변환한다.(파이토치는 기본적으로 실수형이어야 한다.)
predicted = model.predict(data.to(device))
#model.predict()메소드로 순전파 메소드를 호출해 예측값을 구한다.
target = int(label[0])
#라벨을 정수형으로 변환해 target 변수를 저장한다.
total +=1
correct += 1 if(predicted == target) else 0
#예측값과 실제라벨이 비교해 맞을시 correct증가
print('Accuracy: %.4f'%(correct / total))#정확도 계산--> 결과
Accuracy: 0.8511
2. tensorflow로 피마 인디언 데이터 분석하기
- 피마 인디언 데이터를 작업 경로로 가지고 온다.
- 교제 143
1. 라이브러리 선언하기
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns2. csv파일 읽기
df = pd.read_csv('data/pima-indians-diabetes3.csv')
df.head(10)--> 결과

3. 칼럼 값 개수 계산하기
df['diabetes'].value_counts()
#diabetes 칼럼의 개수를 계산한다, 0이 몇개이고 1이 몇개인지 알수있다.--> 결과
0 500
1 268
Name: diabetes, dtype: int64----------
df.info()
#데이터 프레임 정보를 요약한다.--> 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pregnant 768 non-null int64
1 plasma 768 non-null int64
2 pressure 768 non-null int64
3 thickness 768 non-null int64
4 insulin 768 non-null int64
5 bmi 768 non-null float64
6 pedigree 768 non-null float64
7 age 768 non-null int64
8 diabetes 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB4. 데이터프레임 요약하기
df.describe()
5. 데이터 프레임 상관관계
df.corr()--> 결과

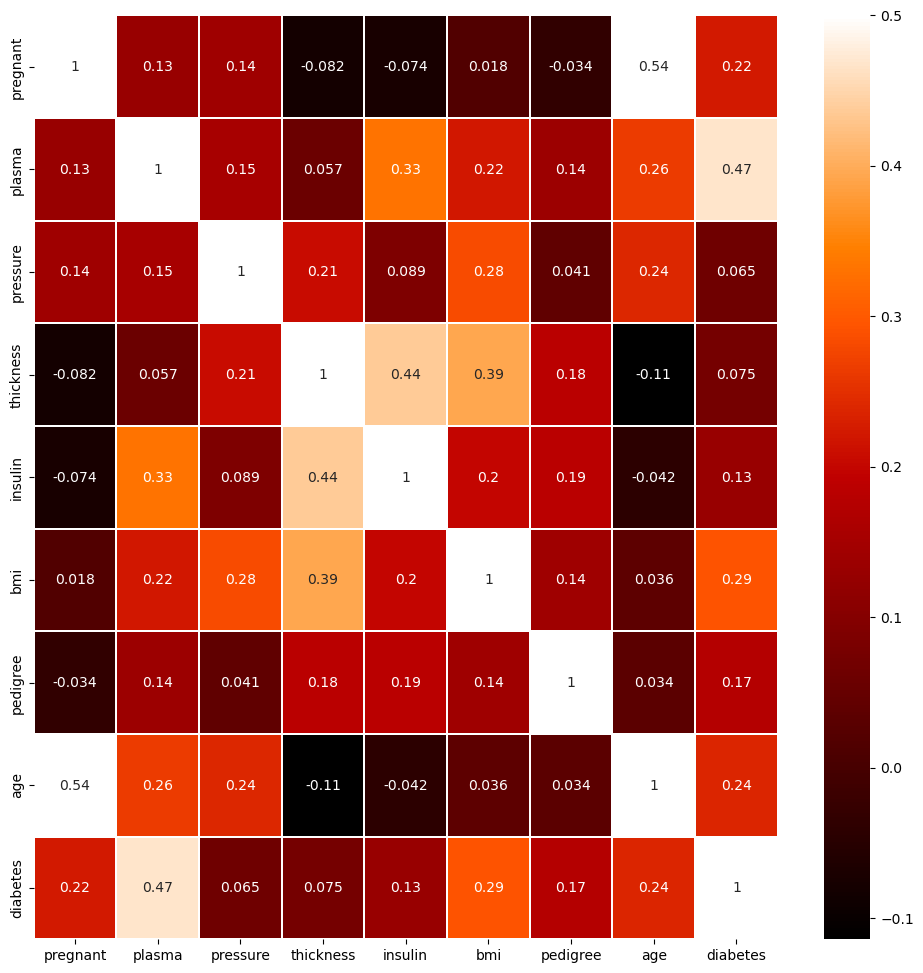
6. 그래프 출력하기
colormap = plt.cm.gist_heat #그래프의 색상 구성을 정합니다.
plt.figure(figsize=(12,12)) #그래프의 크기를 정합니다.
# 그래프의 속성을 결정합니다. vmax의 값을 0.5로 지정해 0.5에 가까울수록 밝은색으로 표시되게 합니다.
sns.heatmap(df.corr(),linewidths=0.1,vmax=0.5, cmap=colormap, linecolor='white', annot=True)
plt.show()--> 결과
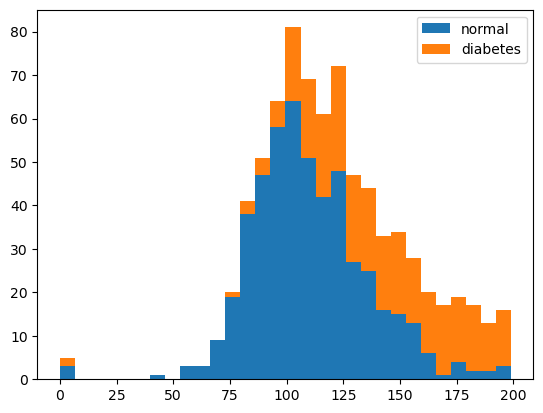
7. 히스토그램 그리기(plasma 값 분포 확인)
plt.hist(x=[df.plasma[df.diabetes==0], df.plasma[df.diabetes==1]], bins=30, histtype='barstacked', label=['normal','diabetes'])
# diabetes칼럼이 0,1일때 plasma열을 선택한다.
# 히스토그램 구간(bin) 개수를 30으로 설정한다.
# batstacked를 설정해 두 히스토그램을 쌓아서 표시한다.
# normal, diabetes로 범례를 지정한다.
plt.legend()
plt.show()--> 결과
8. 히스토그램 그리기(bmi 값 분포 확인)
plt.hist(x=[df.bmi[df.diabetes==0], df.bmi[df.diabetes==1]], bins=30, histtype='barstacked', label=['normal','diabetes'])
plt.legend()
plt.show()--> 결과

9. 딥러닝 모델 생성
X = df.iloc[:,:-1]
#입력데이터, 모든행과 마지막 열을 제외한 모든열을 선택해 데이터 저장
y = df.iloc[:,-1]
#타겟변수, 모든행과 미자막 열만 선택한다.from tensorflow.keras import models, layers
model = models.Sequential()
#딥러닝 모델 선정,Sequential은 순차적으로 층을 쌓는 방식으로 모델을 만든다.
model.add(layers.Dense(12,input_dim=8, activation='relu'))
model.add(layers.Dense(8,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))- 이전 출력값이 다음에서는 입력으로 들어간다.
dense_3
W = input(8) * output(12) = 96
B = 12
W + B = 108
dense_4
W = input(12) * output(8) = 96
B = 8
W + B = 104
dense_5
W = input(8) * output(1) = 8
B = 1
W + B = 9
total = 108 + 104 + 9 = 221
print(model.summary())--> 결과
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 12) 108
dense_1 (Dense) (None, 8) 104
dense_2 (Dense) (None, 1) 9
=================================================================
Total params: 221
Trainable params: 221
Non-trainable params: 0
_________________________________________________________________
None10. 모델학습
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
#model.compile: 케라스에서 모델을 컴파일하는 메소드이다.
#loss: 손실함수, 모델이 학습하는 동안 최소화하려는 오차정의,
#binary_crossentropy는 이진분류에서 사용되는 손실함수이다.
#true/false 처럼 2개의 클래스를 분류할 수 있는 모델로 예측값은 0과 1사이의 확률값이다.
#optimizer: 모델이 손실함수를 최소화하는 방향으로 가중치 조정, adam 방법을 이용
#metrics: 모델의 평가지표 지정, 학습과정에서 모델의 성능 평가
#accuracy는 정확도를 계산한다.h = model.fit(X,y,epochs=100,batch_size=5)
#model.compile로 모델 학습과정 설정후 model.fit으로 모델을 학습시킨다.
#X: 입력데이터, 모델에 입력할 특징데이터
#y: 타겟데이터, 모델이 학습할 정답(label)데이터
#epochs: 학습과정에서 데이터를 몇번 반복해 학습할지 결정
#batch_size: 한번에 처리할 샘플 데이터의 개수 지정--> 결과
Epoch 1/100
154/154 [==============================] - 1s 1ms/step - loss: 3.0909 - accuracy: 0.5065
Epoch 2/100
154/154 [==============================] - 0s 1ms/step - loss: 1.1490 - accuracy: 0.5547
Epoch 3/100
154/154 [==============================] - 0s 1ms/step - loss: 0.9783 - accuracy: 0.5612
Epoch 4/100
154/154 [==============================] - 0s 1ms/step - loss: 0.9023 - accuracy: 0.5755
Epoch 5/100
154/154 [==============================] - 0s 1ms/step - loss: 0.7558 - accuracy: 0.6211
...
Epoch 96/100
154/154 [==============================] - 0s 991us/step - loss: 0.5098 - accuracy: 0.7526
Epoch 97/100
154/154 [==============================] - 0s 1ms/step - loss: 0.5069 - accuracy: 0.7578
Epoch 98/100
154/154 [==============================] - 0s 1ms/step - loss: 0.5014 - accuracy: 0.7604
Epoch 99/100
154/154 [==============================] - 0s 2ms/step - loss: 0.4951 - accuracy: 0.7591
Epoch 100/100
154/154 [==============================] - 0s 3ms/step - loss: 0.5211 - accuracy: 0.75522. torch로 피마 인디언 데이터 분석하기
1. 라이브러리 선언, Pima 클래스 생성하기
import torch
import numpy as np
# 파이토치와 numpy를 임포트한다.
import torch.nn as nn
# 파이토치 신경망 모듈을 임포트한다.
import torch.optim as optim
#최적화 알고리즘을 제공하는 optim을 임포트한다.
from torch.utils.data import DataLoader, TensorDataset
#dataloader와 tensordataset을 임포트한다.device = ('cuda' if torch.cuda.is_available() else 'cpu')
#현재 cpu를 사용하는지 gpu를 사용하는지를 알려준다.data_set = np.loadtxt('data/pima-indians-diabetes3.csv', delimiter=',',skiprows=1)
#numpy에서는 첫줄을 빼야한다.
#그래서 csv파일을 로드할때 skiprows=1을 선언해야한다.
data_set = torch.from_numpy(data_set)
#numpy배열은 data_set을 텐서로 변환한다.
X = data_set[:, :-1]
#입력데이터 X를 정의한다.
y = data_set[:, -1]
#타겟데이터 y를 정의한다.#인공신경망 모벨 Pima를 생성한다.
class Pima(nn.Module):
def __init__(self):
super(Pima, self).__init__()
self.hidden_linear1 = nn.Linear(8,12)
self.hidden_activation1 = nn.ReLU()
self.hidden_linear2 = nn.Linear(12,8)
self.hidden_activation2 = nn.ReLU()
self.output_linear = nn.Linear(8,1)
self.output_activation = nn.Sigmoid()
def forward(self, x):
x = self.hidden_linear1(x)
x = self.hidden_activation1(x)
x = self.hidden_linear2(x)
x = self.hidden_activation2(x)
x = self.output_linear(x)
x = self.output_activation(x)
return x
def predict(self, x):
pred = self.forward(x)
if pred >=0.5:
return 1
else:
return 0model = Pima().to(device)
model--> 결과
Pima(
(hidden_linear1): Linear(in_features=8, out_features=12, bias=True)
(hidden_activation1): ReLU()
(hidden_linear2): Linear(in_features=12, out_features=8, bias=True)
(hidden_activation2): ReLU()
(output_linear): Linear(in_features=8, out_features=1, bias=True)
(output_activation): Sigmoid()
)2. 파리미터 개수
def count_parameters(model):
total_param = 0
for name, param in model.named_parameters():
if param.requires_grad:
num_param = np.prod(param.size())
if param.dim() > 1:
print(name, ':', ' x '.join(str(x) for x in list(param.size())[::-1]), '=', num_param)
else:
print(name, ':', num_param)
print('-' * 40)
total_param += num_param
print('total:', total_param)count_parameters(model)--> 결과
hidden_linear1.weight : 8 x 12 = 96
hidden_linear1.bias : 12
----------------------------------------
hidden_linear2.weight : 12 x 8 = 96
hidden_linear2.bias : 8
----------------------------------------
output_linear.weight : 8 x 1 = 8
output_linear.bias : 1
----------------------------------------
total: 2213. 손실값 출력
ds = TensorDataset(X,y)
dataloader = DataLoader(ds, batch_size=5)
optimizer = optim.Adam(model.parameters())
loss_fn = nn.BCELoss()
n_epochs = 100
for epoch in range(n_epochs):
for data, label in dataloader:
out = model(data.type(torch.FloatTensor).to(device)) #forward propagation
loss = loss_fn(out, label.type(torch.FloatTensor).unsqueeze(1).to(device))#calculate loss
#unsqieeze: 차원을 늘려준다.
optimizer.zero_grad()
loss.backward() #개별 파라미터 기울기 계산
optimizer.step() #개별 파라미터 갱신
#loss와 step은 한세트이다.
print("Epoch: %d, Loss: %.4f"%(epoch, float(loss)))--> 결과
Epoch: 0, Loss: 0.4012
Epoch: 1, Loss: 0.3935
Epoch: 2, Loss: 0.3919
Epoch: 3, Loss: 0.4002
Epoch: 4, Loss: 0.3951
Epoch: 5, Loss: 0.3883
...
Epoch: 94, Loss: 0.3457
Epoch: 95, Loss: 0.3511
Epoch: 96, Loss: 0.3468
Epoch: 97, Loss: 0.3399
Epoch: 98, Loss: 0.3403
Epoch: 99, Loss: 0.33704. 정확도 출력
train_loader = DataLoader(ds)
correct = 0
total = 0
with torch.no_grad():
for data, label in train_loader:
data = data.type(torch.FloatTensor)
predicted = model.predict(data.to(device))
target = int(label[0])
total +=1
correct += 1 if(predicted == target) else 0
print('Accuracy: %.4f'%(correct / total))--> 결과
Accuracy: 0.77733. 다중 분류 문제
- 꽃 데이터를 작업하는 경로에 넣어준다.
1. csv파일 로드하기
import pandas as pd
df = pd.read_csv('./data/iris3.csv')df.head()--> 결과

2. 요약정보 출력
df.info()--> 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB3. 데이터프레임 시각화
import seaborn as sns
import matplotlib.pyplot as plt
# 그래프로 확인해 봅시다.
sns.pairplot(df, hue='species');
#seaborn 라이브러리로 df의 각 변수들 같의 관계를 시각화한다.
#species는 열에 따라 데이터포인트들을 색상으로 구분해 그래프에 표시한다.
plt.show()--> 결과

4. 출력, 타겟변수 선언하기
X=df.iloc[:,:-1]
y=df.iloc[:,-1]print(y[:10]) #정수여야 함--> 결과
0 Iris-setosa
1 Iris-setosa
2 Iris-setosa
3 Iris-setosa
4 Iris-setosa
5 Iris-setosa
6 Iris-setosa
7 Iris-setosa
8 Iris-setosa
9 Iris-setosa
Name: species, dtype: object5. 원-핫 인코딩
y=pd.get_dummies(y)
#원-핫 인코딩으로 범주형 변수를 처리하기 위해 사용된다.
# 단어 집합의 크기를 벡터의 차원으로 하고,
# 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고,
# 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식이다.print(y[:10])--> 결과
Iris-setosa Iris-versicolor Iris-virginica
0 1 0 0
1 1 0 0
2 1 0 0
3 1 0 0
4 1 0 0
5 1 0 0
6 1 0 0
7 1 0 0
8 1 0 0
9 1 0 0- y의 Iris-setosa, Iris-versicolor, Iris-virginica 중 어느 값인지 나타낸다.
- 예를들어, y의 값이 Iris-setosa이면 1이고 나머지는 0으로 표시된다.
print(y[-10:])--> 결과
Iris-setosa Iris-versicolor Iris-virginica
140 0 0 1
141 0 0 1
142 0 0 1
143 0 0 1
144 0 0 1
145 0 0 1
146 0 0 1
147 0 0 1
148 0 0 1
149 0 0 16. 파라미터 계산
from tensorflow.keras import models, layers
model = models.Sequential()
model.add(layers.Dense(12,input_dim=4, activation='relu'))
model.add(layers.Dense(8,activation='relu'))
model.add(layers.Dense(3,activation='softmax'))print(model.summary())--> 결과
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 12) 60
dense_1 (Dense) (None, 8) 104
dense_2 (Dense) (None, 3) 27
=================================================================
Total params: 191
Trainable params: 191
Non-trainable params: 0
_________________________________________________________________
None7. 모델학습
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
#model.compile로 모델을 컴파일한다.
#categorical_crossentropy는 다중 클래스 분류 문제에서 사용되는 손실함수로
#신경망의 출력과 실제 타겟 데이터 사이의 차이를 계산하여 손실을 구하는데 사용된다.
#최적화는 adam을 사용하고 accuracy를 선언해 모델의 평가기준을 정확도로 한다.
h = model.fit(X,y,epochs=30,batch_size=5)
#X입력데이터와 y의 타겟데이터로 전체데이터를 30번 반복학습하고
#한번에 5개의 샘플을 사용해 가중치를 갱신한다.--> 결과
Epoch 1/30
30/30 [==============================] - 1s 1ms/step - loss: 1.5971 - accuracy: 0.3333
Epoch 2/30
30/30 [==============================] - 0s 1ms/step - loss: 1.2213 - accuracy: 0.6067
Epoch 3/30
30/30 [==============================] - 0s 1ms/step - loss: 1.0170 - accuracy: 0.6667
Epoch 4/30
30/30 [==============================] - 0s 1ms/step - loss: 0.8723 - accuracy: 0.6667
...
Epoch 27/30
30/30 [==============================] - 0s 1ms/step - loss: 0.3443 - accuracy: 0.9400
Epoch 28/30
30/30 [==============================] - 0s 1ms/step - loss: 0.3259 - accuracy: 0.9533
Epoch 29/30
30/30 [==============================] - 0s 1ms/step - loss: 0.3150 - accuracy: 0.9533
Epoch 30/30
30/30 [==============================] - 0s 1ms/step - loss: 0.2902 - accuracy: 0.95334. 다중 분류 문제(파이토치)
1. 라이브러리 선언, csv로드하기
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDatasetdevice = ('cuda' if torch.cuda.is_available() else 'cpu')import pandas as pd
df = pd.read_csv('./data/iris3.csv')df.tail()--> 결과

2. 입력과 타겟변수 선언하기
X=df.iloc[:,:-1]
y=df.iloc[:,-1]X.info()--> 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
dtypes: float64(4)
memory usage: 4.8 KB3. numpy타입으로 텐서 타입으로 바꾸기
X=torch.from_numpy(X.values)print(type(X))--> 결과
<class 'torch.Tensor'>4. 원-핫 인코딩 수행하기
y = pd.get_dummies(y)
y = torch.from_numpy(y.values)
print(type(y))--> 결과
<class 'torch.Tensor'>5. 데이터 출력하기
print(y[:10]) #iris-setosa일때는 1로 되고 다른 꽃들은 0으로 된다.--> 결과
tensor([[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[1, 0, 0],
[1, 0, 0]], dtype=torch.uint8)6. 인공신경망 Iris 만들기
class Iris(nn.Module):
def __init__(self):
super(Iris, self).__init__()
self.hidden_linear1 = nn.Linear(4,12)
self.hidden_activation1 = nn.ReLU()
self.hidden_linear2 = nn.Linear(12,8)
self.hidden_activation2 = nn.ReLU()
self.output_linear = nn.Linear(8,3)
def forward(self, x):
x = self.hidden_linear1(x)
x = self.hidden_activation1(x)
x = self.hidden_linear2(x)
x = self.hidden_activation2(x)
x = self.output_linear(x)
return xmodel = Iris().to(device)
model--> 결과
Iris(
(hidden_linear1): Linear(in_features=4, out_features=12, bias=True)
(hidden_activation1): ReLU()
(hidden_linear2): Linear(in_features=12, out_features=8, bias=True)
(hidden_activation2): ReLU()
(output_linear): Linear(in_features=8, out_features=3, bias=True)
)7. 파라미터 개수 세기
def count_parameters(model):
total_param = 0
for name, param in model.named_parameters():
if param.requires_grad:
num_param = np.prod(param.size())
if param.dim() > 1:
print(name, ':', ' x '.join(str(x) for x in list(param.size())[::-1]), '=', num_param)
else:
print(name, ':', num_param)
print('-' * 40)
total_param += num_param
print('total:', total_param)count_parameters(model)--> 결과
hidden_linear1.weight : 4 x 12 = 48
hidden_linear1.bias : 12
----------------------------------------
hidden_linear2.weight : 12 x 8 = 96
hidden_linear2.bias : 8
----------------------------------------
output_linear.weight : 8 x 3 = 24
output_linear.bias : 3
----------------------------------------
total: 1918. 손실값 출력하기
ds = TensorDataset(X,y)
dataloader = DataLoader(ds, batch_size=5)
optimizer = optim.Adam(model.parameters())
loss_fn = nn.CrossEntropyLoss()
n_epochs = 30
for epoch in range(n_epochs):
for data, label in dataloader:
out = model(data.type(torch.FloatTensor).to(device)) #forward propagation
loss = loss_fn(out, label.type(torch.FloatTensor).to(device))#calculate loss
#unsqieeze: 차원을 늘려준다.
optimizer.zero_grad()
loss.backward() #개별 파라미터 기울기 계산
optimizer.step() #개별 파라미터 갱신
#loss와 step은 한세트이다.
print("Epoch: %d, Loss: %.4f"%(epoch, float(loss)))--> 결과
Epoch: 0, Loss: 0.5206
Epoch: 1, Loss: 0.6155
Epoch: 2, Loss: 0.6569
Epoch: 3, Loss: 0.6708
Epoch: 4, Loss: 0.6322
...
Epoch: 25, Loss: 0.5210
Epoch: 26, Loss: 0.5210
Epoch: 27, Loss: 0.5215
Epoch: 28, Loss: 0.5206
Epoch: 29, Loss: 0.51969. 정확도 구하기
test_loader = DataLoader(ds, batch_size=5)
correct = 0
flag = True
with torch.no_grad():
for data, label in test_loader:
output = model(data.type(torch.FloatTensor).to(device))
pred = output.max(1)[1] #output을 1번째 차원으로 max하여 그 index 추출
target = label.max(1)[1]#label을 1번째 차원으로 max하여 그 index 추출
if flag :
print("output",output)
print("output.max(0)",output.max(0))#output에서 열 기준으로 최대값을 추출한다.
print("output.max(1)",output.max(1))#output에서 행 기준으로 최대값을 추출한다.
print('-'*30)
print("label.max(0)",label.max(0))#label에서 열 기준으로 최대값을 추출한다.
print("label.max(1)",label.max(1))#label에서 행 기준으로 최대값을 추출한다.
flag = False
correct += pred.eq(target.to(device)).sum().item()
#[0,0,0,0,0]과 [0,0,0,0,0]이런식으로 반환시 0끼리 같으면 1을 반환하고 틀리면 0을 반환한다. 즉, 전부다 맞을 경우 5를 반환한다.
print('\nTest set: Accuracy: {}/{} ({:f})\n'.format(correct, len(test_loader.dataset), correct / len(test_loader.dataset)))
#correct은 일치한 횟수, len쪽은 전체 횟수, /쪽은 정확도이다.
print("Accuracy: %f" % (correct / len(test_loader.dataset)))--> 결과
output tensor([[ 0.8066, 0.1407, -0.7902],
[ 0.7740, 0.1257, -0.7562],
[ 0.7592, 0.1189, -0.7407],
[ 0.7436, 0.1118, -0.7245],
[ 0.7985, 0.1370, -0.7818]])
output.max(0) torch.return_types.max(
values=tensor([ 0.8066, 0.1407, -0.7245]),
indices=tensor([0, 0, 3]))
output.max(1) torch.return_types.max(
values=tensor([0.8066, 0.7740, 0.7592, 0.7436, 0.7985]),
indices=tensor([0, 0, 0, 0, 0]))
------------------------------
label.max(0) torch.return_types.max(
values=tensor([1, 0, 0], dtype=torch.uint8),
indices=tensor([0, 0, 0]))
label.max(1) torch.return_types.max(
values=tensor([1, 1, 1, 1, 1], dtype=torch.uint8),
indices=tensor([0, 0, 0, 0, 0]))
Test set: Accuracy: 120/150 (0.800000)
Accuracy: 0.800000- 3일차는 내용을 좀더 손보고 올리겠습니다!